Spatial hearing in middle-aged and older adults with a hearing aid: Does noise type matter?
Article information
Abstract
Purpose
The present study aimed to identify the overall patterns of spatial hearing in a sample population of the geriatric population wearing a hearing aid in an actual clinical setting and to investigate while paying attention to aging and the effects of spatial separation on informational masking (IM) of target speech of common types of noise in everyday life.
Methods
Nine participants (mean age: 68.9±9.6) wearing hearing aids participated. The spatial hearing abilities of the participants were assessed by measuring their speech reception threshold (SRT) and spatial release from masking (SRM), using speech-like (SLN) and steady-state (SSN) noise-maskers.
Results
The study results identified a trend in the decrease in SRT in all noise conditions with increasing azimuth angles. The larger the target/masker spatial separation, the larger the SRM became in all noise conditions. Results revealed that geriatric hearing-impaired participants experienced a comparable amount of SRM from IM in SLN concerning SSN.
Conclusions
Given these findings, the spatial separation did not have the same effects on the IM of target speech by SLN in the geriatric population wearing a hearing aid as it did in the general hearing-impaired population at younger ages. It can be inferred from these findings that the extent to which informational maskers can compromise the spatial hearing abilities of geriatric hearing-impaired listeners may depend on their age and the severity of spatial hearing loss being imposed on them.
INTRODUCTION
Human speech perception often involves listening during competing background noise in the modern world. Not surprisingly, speech perception in noise is one of the most common problems that hearing-impaired listeners face daily, even with proper amplification. Hearing aid and cochlear implant (CI) users are more likely to experience difficulties in noisy environments than in quiet environments. The geriatric population that could benefit from amplification are often not satisfied with their hearing instrument users in noisy listening conditions [1].
An auditory process often referred to as spatial hearing, is one of the mechanisms the human brain uses to selectively attend to wanted/desired speech in competing talkers or background noise [2]. Spatial hearing is considered to be situated beyond auditory localization and lateralization. It is also interrelated to both auditory scene analysis and auditory stream segregation [3]. Spatial hearing loss thus describes the lack of enough functional spatial hearing abilities in hearing-impaired listeners to separate target speech from competing noises coming from different directions. Indeed, the spatial hearing begins to decline after age 50, and spatial hearing loss is found in most people over the age of 70 [4,5]. This circumstance means that geriatric hearing-impaired listeners are the most likely to suffer spatial hearing loss.
Several studies have investigated spatial hearing in listeners with normal hearing and simulated hearing loss and a cochlear implant (CI) [6–8]. Some have studied the effects of simulated conductive hearing loss on spatial hearing of normal-hearing children [9,10]. Few studies have attempted to analyze the impact of spatial separation by synthetic noise on the masking of speech in the general hearing-impaired population [11,12]. Despite that issue, most previous studies have been restricted to limited cases of normal-hearing listeners with simulated hearing loss or the general population with hearing loss. These cases were vastly different from the realistic examples of sensorineural hearing loss in older people with a hearing aid in the late middle to late adulthood, where age-related factors become the crucial points to consider.
It is generally believed that the characteristics of the spatial hearing of the hearing aid and the CI wearer are different. It has been shown that the target/masker spatial separation can benefit CI users as much as normal hearing subjects, using the moving noise source generated through wave field synthesis [6]. However, more recently, there has been an increasing demand to investigate the effects of environmental noise on the spatial hearing of geriatric hearing aid users in a real clinical setting. In the current study, competing noise was presented as the two commonly found types of noise in everyday life: the steady-state (SSN) and speech-like (SLN) noise-maskers. Listeners in everyday situations are often more often confronted with competing sounds of many voices talking at once at spatially discrete locations rather than broadband white noise. These voices can be perceived as similar to the target speech and thus can be considered as informational masking (IM) [13]. In addition to that IM, energetic masking (EM) also exists where the noise can physically interfere with the speech signal [14]. Speech perception is associated with EM during the SSN masker, such as speech-shaped noise, broadband white noise, and speech babble. The SSN masker is considered a primarily energetic masker. In contrast, the SLN masker, such as competing speech, is generally regarded as a primarily informational masker, although it involves both EM and IM. The current study identified the overall patterns in the spatial hearing abilities of the sample population of geriatric hearing aid users in a real clinical setting. By paying attention to aging, it then investigated the effects of spatial separation on the IM of target speech by the SLN relative to SSN noises.
METHODS
Participants and materials
Nine participants with an average age of 68.9±9.6 and between 54 and 83 in age took part in the study. The participants were Korean-speaking hearing aid users with cochlear origin hearing loss. Figure 1 shows the participants’ distribution of unaided and aided hearing thresholds. All experiments were conducted in a sound-treated booth in the university clinic equipped with multiple loudspeakers arranged in a semi-circular horizontal plane at 45° steps and spanning a full 180°. All loudspeakers were placed along this semi-circular shape, with participants sitting at the centre. Participants were seated in a chair and facing the centre of the speaker array at the front (0° azimuth).

Mean hearing thresholds of unaided and aided in participants. Error Bar means standard deviations.
The target speech stimuli were the sentences from the Korean version of the Oldenburg matrix test, the Korean matrix sentences test, spoken by a female adult speaker of standard Korean [15]. The Korean matrix sentences were generated from a 10-by-5 matrix of 50 words (e.g., ten words per each of 5 categories- name, adjective, noun, number, and verb). These seemingly random sentences generated from the 50-word base matrix consisted of the most used words in the spoken Korean language and were impossible to memorize. The familiarity of the words used in the Korean matrix sentences minimized the influence of the participants’ linguistic competence in speech intelligibility.
The steady-state noise (SSN) masker used in this study was speech-shaped stationary noise with a long-term spectrum that matched the long-term spectrum of the target speech material. The speech-like noise (SLN) masker used for this study was the two-talker speech masker consisting of two different edited recordings of voices of two talkers (one female and one male) discussing various topics. Each record was edited to remove silent pauses that were 200 milliseconds or greater. The two recordings were mixed in an overlapping manner to counteract the glimpsing effect. Speech stimuli and noise-maskers had a resolution of 32 bits and a sampling rate of 44.1 kHz. These files were root-mean-square (RMS) normalized to have multiple tracks sounding equally loud. The volume was adjusted so that the loudest peak of the speech stimuli was equal to the maximum signal used in the noise masker.
Procedures
The spatial hearing of the participants was measured by obtaining the speech reception threshold (SRT) and spatial release from this masking (SRM). SRT is defined as dB SNR as the relative level of a target sentence, at which 50% of the words are understood correctly amidst competing speech/noise. The SRM corresponds to the benefit of target/masker spatial separation and is often used to measure the listener’s spatial hearing ability to use inter-aural cues to separate the target speech signal from the background noise in complex listening environments. In this current study, an existing time-efficient algorithm was modified from QuickSIN and BKB-SIN for clinical purposes for the multiple loudspeaker arrays, using verified speech stimuli and noise maskers. As was the case in QuickSIN and BKB-SIN, the Spearman-Kärber equation was used to calculate the SRT: [16]
where
pl=the presentation level of the target sentence in dB SNR;
Δ=the amount of dB SNR by which the noise masker level decreases;
∑=the total number of correctly repeated keywords in each list of target sentences;
f=the fixed number of keywords in each target sentence, respectively.
The level of the noise masker was varied in steps of Δ=2 dB relative to that of the target sentence, thus producing different dB SNRs. The assessment test consisted of up to 24 lists of 6 target sentences in each list (female talker) and totaling up to 144 matrix speech test sentences. Five keywords f=5 in each sentence were scored, producing 30 keywords for each list. The noise masker was made louder in 2 dB steps from +8 dB SNR to −2 dB SNR for each subsequent target sentence on each record. Given this set-up, the possible SRT range spanned from 9 dB SNR (worst) to −3 dB SNR (best). The average SRT value for two measurements was computed at each noise-masker configuration. The background noise level varied from positive dB SNR to negative dB SNR relative to the target sentence, which was fixed at either the loud MCL or the fixed SL of (PTA+12.5 dB)+39.5 dB. This level ensured that both the target sentences and the masking noises were audible to the hearing-impaired participants to ensure the overall audibility of the test material. The hearing-impaired listeners needed positive dB SNRs to understand speech in background noise, while normal-hearing listeners could comprehend speech in noise even in negative dB SNRs. The competing noise was presented either as SSN or SLN noise-maskers.
SRM was computed as the difference between S0N0 and one of two fixed maskers: S0N45 and S0N90 as follows:
where
S0 represents a target speech at 0° azimuth; N45 a noise masker at 45° azimuth; and N90 a noise masker at 90° azimuth, respectively. The SRM was calculated as the difference in speech recognition performance (SRT) between a condition where the target and noise masker stimuli were co-located at 0° (denoted herein as S0N0) and a condition where the target and noise masker stimuli were spatially separated (designated herein as S0N45/90).
Statistical analysis
Data analysis was performed using the IBM SPSS version 25 (SPSS INC., Chicago, IL, USA). A two-way ANOVA analysis with repeated variance measures was conducted to evaluate the SRT and SRM results trends. There were two levels of masker (SSN and SLN) and three levels of listening condition (0° azimuth, 45° azimuth, and 90° azimuth). Results from this analysis were then investigated to determine if there was a significant main effect of a masker or listening condition and whether there was no significant interaction between masker and listening condition. A Friedman test for paired comparisons was conducted to calculate a significance value (p-value) to determine whether the difference in SRT and SRM between SSN and SLN masker set-ups was statistically significant as the azimuth angle increased from 0o to 90°. The significant default level was set to 5%.
RESULTS
Figure 2 shows the SRT of the participants obtained for each spatial location, using the SSN and SLN noise-maskers. Figure 3 displays the corresponding values of SRM for all the participants, obtained for each spatial location and using the same noise-maskers. Figure 2 presents the decrease in SRT for all the noise conditions, SSN (p=0.0027), and SLN (p=0.0047), with increasing azimuth angles. The effect of a change in listening condition on SRT was statistically significant (p<0.01). Similarly, the impact of different noise types on SRT was statistically significant: p<0.01 at 0° and 45° azimuths and p<0.05 at 90° azimuths.
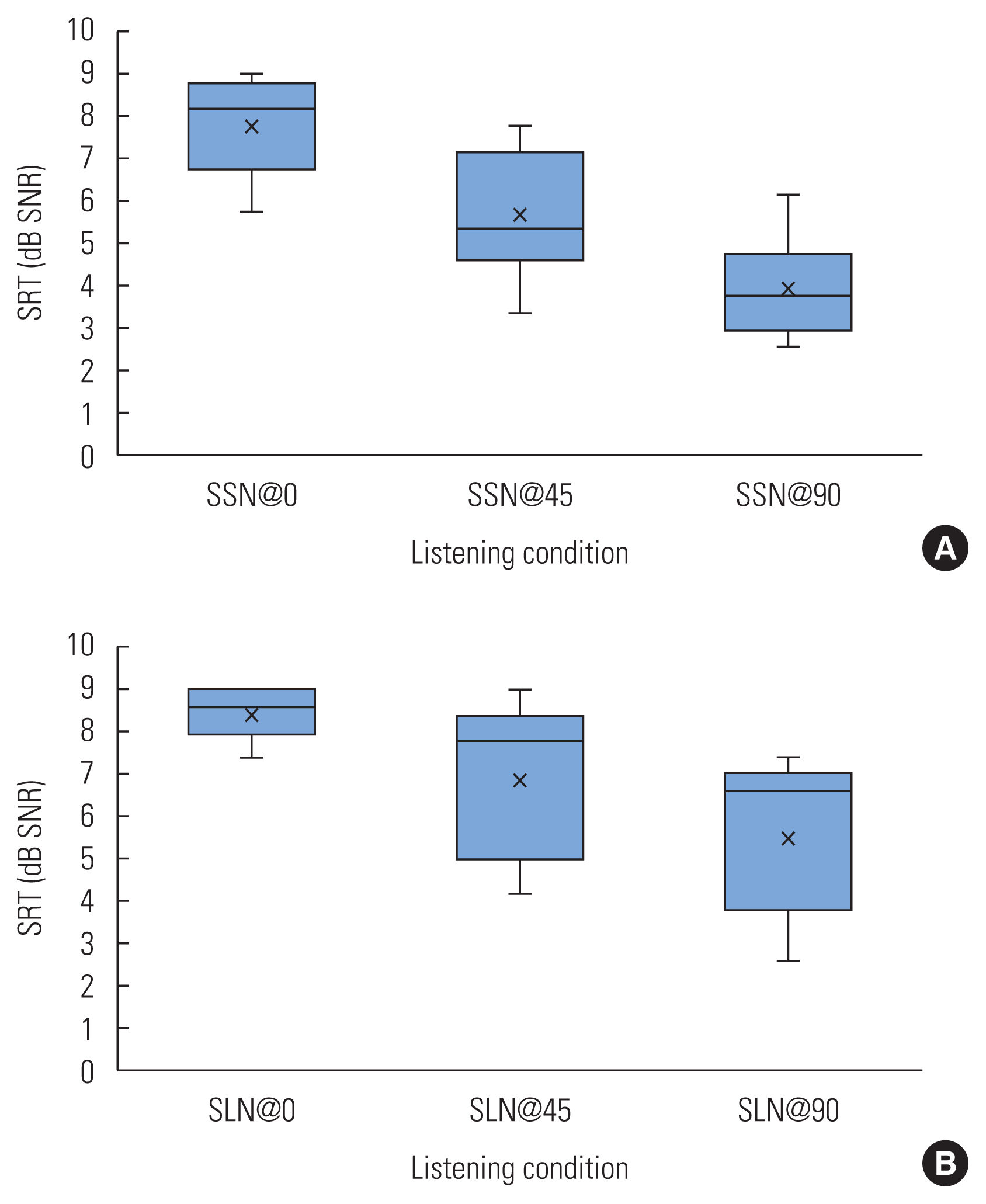
The SRT using steady-state noise (A) and speech-like noise (B) of the participants. SRT, speech reception threshold; SSN, steady-state noise; SLN, speech-like noise.
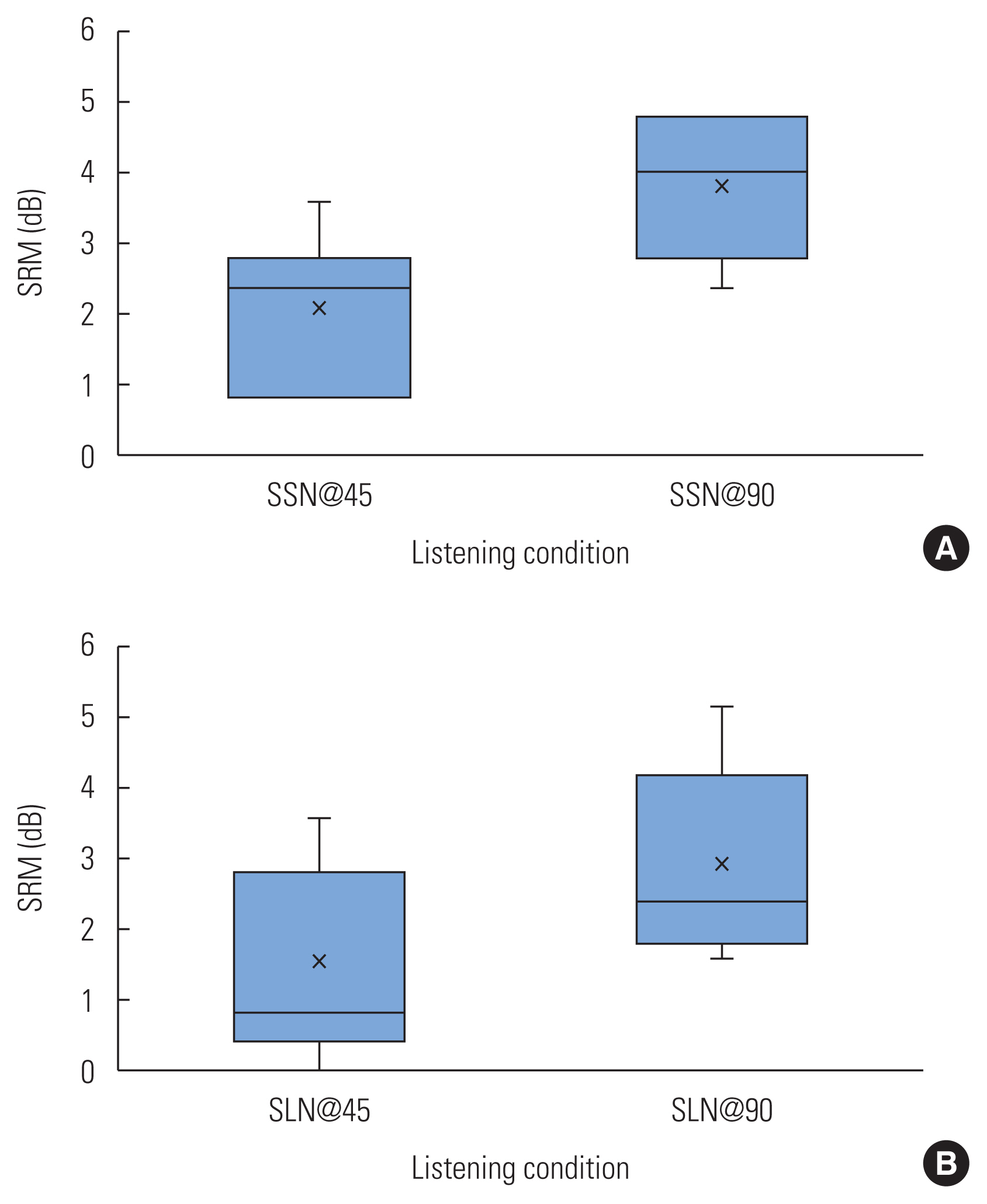
The SRM using steady-state noise (A) and speech-like noise (B) of the participants. SRM, spatial release from this masking; SSN, steady-state noise; SLN, speech-like noise.
However, as shown in Figure 2, the geriatric hearing-impaired participants needed more dB SNR to understand 50% of the target sentences correctly in SLN than required in SSN. Figure 3 shows that the geriatric hearing-impaired individuals achieved as much as a 3.9+1.0 dB advantage of target/masker spatial separation, using the SSN noise-masker. Further, the SRM improved by 1.77+0.49 dB in SSN between 45° to 90°. The benefits of target/masker spatial separation in SLN reached 3.2+1.4 dB. The change in SRM with the increasing azimuths was statistically significant (p<0.01), regardless of the noise types. However, for a given spatial location, the amount of change that the different noise types alone could induce in SRM was statistically insignificant (p>0.05). A two-way ANOVA analysis with repeated measures of variance was conducted to evaluate the SRT and SRM results trends as shown in Figures 2 and 3, respectively. Table 1 reports the results of this analysis. There was a significant main effect of masker (F=37.57, p<0.001) and a significant main effect of listening condition (F=132.16, p<0.001). There was no significant interaction between the noise-masker and the listening conditions.

Results of an SPSS evaluating the effects of masker (SSN, SLN) and listening condition (0° azimuth, 45° azimuth, and 90° azimuth) on Speech Reception Thresholds (SRT) and Spatial Release from Masking (SRM)
DISCUSSION
In recent years, an increasing number of studies have been published that have investigated spatial hearing loss. Still, these were confined to limited cases in the general population with and without hearing loss, which deviated from the realistic examples of geriatric hearing-impaired listeners with spatial hearing loss wherein age-related factors may have played a critical role in these research outcomes. The overall patterns of the test results identified a trend for the decrease in SRT in all noise conditions as the azimuth angle increased from 0° to 90o. The greater the spatial separation between the target and the noise-masker stimuli, the more obvious the benefit of target/masker spatial separation (SRM) became in all noise conditions. The SRT range for normal-hearing individuals was reported to be −8.6±0.9 dB SNR for the American English matrix test [17].
In contrast, bilateral CI users needed SRTs of as much as +6 dB SNR to understand 50% of the target speech correctly in amplitude modulated (AM) noise [6]. This level was comparable to the average SRT value of 7.69±1.3 dB SNR reported in this study for SSN. For normal-hearing listeners, the average SRT was more than 3 dB higher in the two-talker noise-masker than was the speech-shaped noise-masker in most conditions [9]. This result was also the case in this study where the average SRT for hearing-impaired listeners was as much as up to 1.5 dB higher in SLN than in SSN. The normal-hearing individuals were reported to have an average SRM value of 3.7±1.17 dB in SSN [9]. The geriatric hearing-impaired individuals in this study achieved as much as 3.9+1.0 dB advantages of target/masker spatial separation, using the SSN.
This study revealed that although the effects of the different noise types on SRT were statistically significant, the changes in SRM induced by the different masking effects of varying noise types being used were statistically insignificant. For the normal-hearing adults, SRM was found to be approximately 6 dB larger in SLN than in SSN [9]. The general population with and without hearing loss was also reported to have 10 to 15 dB higher SRMs in SLN than in SSN [11]. Contrarily, the geriatric hearing-impaired participants in this study experienced a comparable amount of SRM in the SLN masker, just as they did in the SSN masker, as shown in Figure 3.
Speech perception in SSN is traditionally associated with EM, as the primarily energetic SSN masker does not contain phonological information. The primarily informational SLN masker contains phonological information, potentially affecting linguistic processing. However, speech perception in SLN involves both EM and IM [14]. Any difference between the effects of SSN and SLN on the spatial hearing of hearing-impaired listeners can be attributed to the IM elicited by the SLN.
The target/masker spatial separation will benefit the general population at younger ages more in SLN than in SSN [11,13]. In contrast, this study revealed that the spatial separation did not have the same effects on the IM of target speech by the SLN masker in the geriatric hearing-impaired population as it did in the general population with and without hearing loss. The normal-hearing listeners, regardless of age, were reported to achieve the SRM at a much smaller separation between the target and SLN masker than the geriatric hearing-impaired listeners can acheive [18]. In which cases, the geriatric hearing-impaired listeners obtained very few advantages even at the largest separation tested. The SRM from IM was reported to decline with age, implying that spatial hearing abilities deteriorate with age [19]. It can thus be inferred from these findings that the extent to which the informational maskers can compromise the spatial hearing abilities of geriatric hearing-impaired listeners may depend on age and the severity of spatial hearing loss already imposed on them. It may also mean that, regardless of the competing noise types, geriatric hearing-impaired listeners cannot take the same full advantage of target/masker spatial separation in complex listening environments as their counterparts at younger ages can. Due to Covid-19, it was difficult to recruit more participants, especially the age-matched population without hearing loss. It is a limitation of this study.
In recent years, there has been an increasing interest in including remediation training for spatial hearing loss in the rehabilitation plans for geriatric hearing-impaired listeners. This latest study suggests that remediation training directed explicitly at improving spatial hearing skills could indeed improve the spatial hearing abilities of the geriatric hearing-impaired participants [20]. In the future, research should be made on effective rehabilitation methods to improve the spatial hearing ability in the older population with hearing impairment.
ACKNOWLEDGMENTS
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2019S1A5A2A01039904).
Notes
The authors declare no conflict of interest.