








INTRODUCTION
Face masks have recently been used to block the SARS-CoV-2 virus or COVID-19 virus caused by contact with respiratory droplets in daily life. Since respiratory droplets spread into the air during breathing, coughing, sneezing, or speaking in daily life, wearing masks is still recommended in public as well as in medical settings during the COVID-19 pandemic [1]. To prevent virus infection, patients should also wear a face mask during the voice evaluation procedure.
Voice disorders are medical conditions that often result from vocal abuse/misuse which is referred to generally as vocal hyperfunction. A standard voice evaluation approach is required to accurately diagnose and evaluate hyperfunction of voice. Vocal hyperfunction (VH), defined as excessive laryngeal musculoskeletal activity during phonation, is considered a pathological component in the most frequent behav-ioral voice disorders [2–4]. One of the most frequent com-plaints in VH patients is the demand for increased voice effort to speak [5,6]. Some self-report data have shown that healthy speakers perceived a significantly increased voice effort and vocal tract discomfort while wearing masks [7–9]. These findings may imply that there can be as an additional vocal effort to increase the voice intensity unconsciously when wearing a face mask. Vocal effort or effortful speaking is an important factor in voice disorder and is considered an element of hyperfunctional voice disorder [10]. Therefore, increased vocal effort due to the face mask may give a risk of developing a functional voice disorder in healthy population or deteriorate voice quality in dysphonic patients.
Acoustic evaluation is a widely used non-invasive objective procedure for testing laryngeal function with respect to un-derlying vocal fold physiology and pathology [11]. A recent study has shown that wearing a face mask acoustically affected voice signals. Even if a patient suspected of voice disorder visits a voice clinic, infection can be prevented only when a mask is still worn during voice evaluation, and whether acoustic measurement changes due to wearing a mask are becoming a significant clinical issue. Therefore, investigating the effects of face masks on voice and speech signals is important for clinical determination and mask selection for reliable voice evaluation in COVID-19 pandemic settings.
The recent study found that type of mask, especially in KF94 mask affected speech handicap and vocal tract discomfort than surgical or fabric mask in healthy populations [12]. Re-gardless of the type of mask, it has been reported that it has the effect of reducing the vocal intensity in the mid- and high- frequency range in the healthy populations [13–18]. However, prior studies using healthy speakers have shown that certain mask types do not affect acoustic voice signals. In particular, the surgical mask did not acoustically affect the voice or speech signal, and there was no significant difference in acoustic perturbation measurements such as fundamental frequency (F0), jitter, shimmer, and harmonic to noise ratio (HNR), including voice intensity than wearing either no mask or a KN 95 mask, when wearing the surgical mask. These results may not differ significantly from the actual conditions without masks [19]. On the other hand, the HNR values were significantly increased with the wearing a mask, either a surgical or a KN95 when compared to the unmasked condition [19,20].
A cepstral-based measure is recommended based on in-creasing evidence that cepstral peak prominence (CPP) is the most promising acoustic measure of voice quality and overall level of noise in the voice signal [21–23]. This can be valid for severe dysphonia and for relative short duration sustained vowel compared to some time-based traditional measures (e.g., jitter, shimmer) [11]. Moreover, spectral-based measure such as ratio of low-to-high frequency spectral energy showed considerable promise as an objective measure of dysphonia severity in continuous speech, even across the diverse voice types [24]. Several studies also measured CPP and there was none or minimally changes with mask-wearing [14,19,20, 25].
Although many studies reported about mask effect on acoustical chagnes, little is known concering the effect of the acoutical measures in patietns with voice disorders. The knowledge of whether face masks can cause acoustic changes is of paramount for clinicians to identify the hyperfunctional voice disorder. From this point of view, this study was aimed to examine the effect of face masks on acoustic voice and speech parameters in patients with hyperfunctional dysphonia.
METHODS
Participants
A total of 20 patients with hyperfunctional voice disorders (14 females, 6 males, age=30.55±8.24) and 20 normal adults (15 females, 5 males, age=27.31±7.52) were enrolled. Patients group included 10 vocal nodules (50%), 6 muscle tension dysphonia (30%), and 4 adductor spasmodic dysphonia (20%) who diagnosed by a laryngologist, while age- and gender- matched normal participants were selected as those who had no upper respiratory tract infection, no laryngeal disease in the last three months, no voice, hearing, and neurological lan-guage problems, no smoking experience, and ‘G0’ in the GRBAS scale evaluated by two certified experienced speech-language pathologists who specializing in voice disorders. All participants were agreed to take part in this study.
Voice recordings and data analysis
Voice recording for collecting voice samples of participants was performed in a quiet environment as much as possible. In this study, a voice recorder (PCM Recorder, PCM-M10, Sony, Japan) was used to collect voice samples, and recording was performed at a distance of about 10-15 cm from the mouth at an angle of 45 degrees on the side of the subjects. Using the Computerized Speech Lab (Model 4150B; KayPENTAX Medical Company, Lincoln Park, NJ, USA), sustained /a/ vowel and speech samples (3rd CAPEV sentence- all voiced sentence and 2nd sentence of the Korean standard passage the ‘Kaeul’(Autumn)) were recorded at their habitual pitch and loudness[26]. In order to examine the acoustical effects of face mask condition for each person, three types of mask condition (no mask, surgical mask, KF94) were performed in ran-dom order. Similarly, different speech tasks were repeatedly performed on the same person to examine the effect of speech tasks on the acoustic characteristics due to wearing the face masks.
When collecting voice samples in an environment without a mask, there is a risk of COVID-19 infection, so the researcher recorded voice samples by maintaining sufficient distance from the subject while wearing a mask. Voice sample collection was conducted and recorded 1:1 for each subject in a room where the noise was blocked as much as possible. All recordings were carried out in compliance with the COVID-19 quarantine rules, and after one recording was completed, the spray was disinfected through a disinfectant. After a sufficient time, recording of the following subjects was performed, and the researcher and all subjects were hand-disinfected by a hand using hand sanitizer provided before and after entering the room.
All voice files were recorded and saved as wav. extension files. Voice samples were edited to extract the middle 3 secods of the sustained /a/ vowel, excluding 1 second at the begin-ning and end of one of the three samples of 5 seconds. Traditional acoustic measures such as fundamental frequency, jitter, shimmer, and NHR were measured with sustained /a/ vowel using the Multi-Dimensional Voice Program (Model 5105, KayPENTAX, Lincoln Park, NJ, USA, MDVP). With perturbation measures, CPP, L/H ratio, and standard deviations (sd) of CPP and L/H ratio for the vowel and sentence samples were also measured using the Analysis of Dysphonia in Speech and Voice (Model 5109, KayPENTAX, Lincoln Park, NJ, USA, ADSV) software program.
Statistical analysis
One-way repeated measures ANOVA was carried out for veri-fying the differences of acoustic measurements with different mask conditions (no mask, surgical, and KF94 mask) for the patient and healthy group. One-way repeated measures ANOVA was also performed to examine speech tasks’ effect on acoustic measures for each mask condition. Significant main effects of mask condition were evaluated with the Bon-ferroni test. When Mauchly's sphericity test assumed sphericity, the sphericity assumption value of the effect test within the individual was used, and when the sphericity assumption was not satisfied, the freedom and F values modified by Greenhouse-Geisser were used. SPSS version 25.0 (IBM Corp., Armonk, NY, USA) was used for statistical analysis, and a significance level of 0.05 was employed.
RESULTS
Perturbation measures
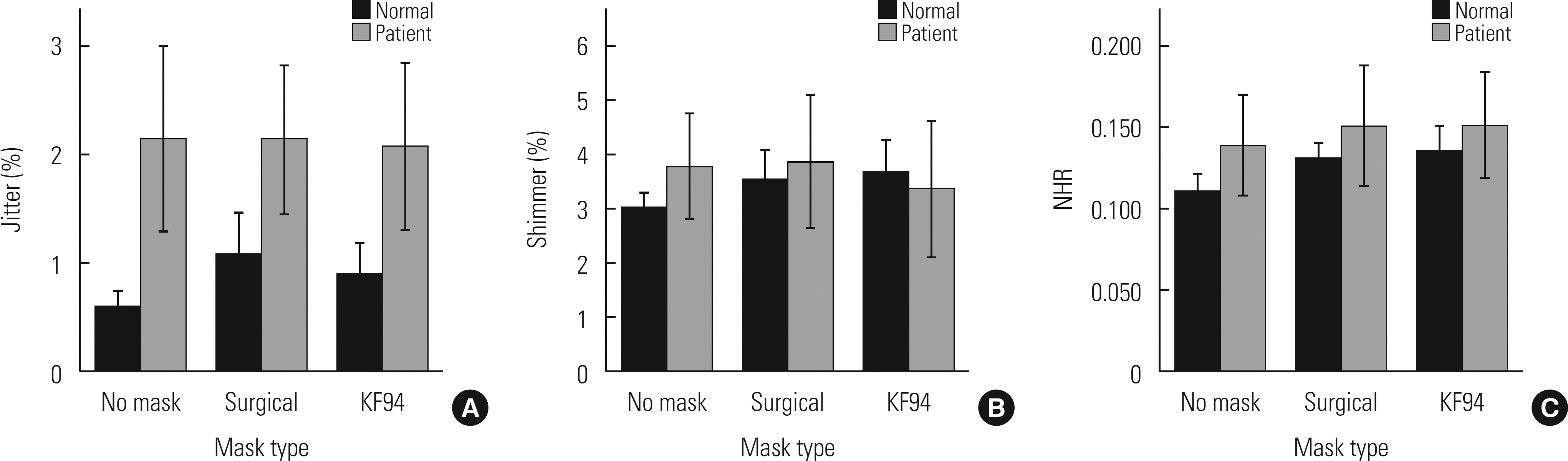
Descriptive data and comparison of the acoustic perturbation measures of patients with hyperfunctional voice disorder and healthy population groups across different mask conditions are shown in Table 1.
Table 1.
Comparisons of perturbation acoustic measures for 3 different mask conditions (no mask, surgical, KF94) within each patient and healthy population
One-way repeated ANOVA showed that there were no significant differences in jitter (F(1.450, 27.556)=0.091, p =0.853), shimmer (F(2, 38)=0.950, p =0.396), and NHR (F(2,38)=0.837, p =0.441) for the patient group. Both F0 of male and female patients did not also differ among the different mask conditions (p >0.05).
On the other hand, for the healthy populations, significantly lower jitter (F(2,38)=5.234, p =0.011), shimmer (F(2, 38)= 3.456, p =0.042), and NHR (F(2, 38)=7.451, p =0.002) were found in no mask condition than a surgical or a KF 94 mask, while there were no significant differences in male f0 (p >0.05), female f0 (p >0.05) (Fig. 1).
Vocal intensity
Table 2 shows the means and standard deviations of vocal intensity (dB) in each mask condition with different speech tasks for the normal and patient group.
Table 2.
Comparison of vocal intensity with different voice and speech tasks for each different mask condition (no mask, surgical, KF94) between patient and healthy population groups
Vocal intensity of /a/ vowel was significantly different among the different mask conditions in the healthy group (F(2, 38)=16.830, p =0.000). Post-hoc analysis showed that no-mask condition significantly increased the vocal intensity more than a surgical (p =0.000) or a KF94 mask (p =0.000) condition. However, vocal intensity did not differ in the patient group (F(2, 38)=2.319, p =0.112).

Cepstral & spectral measures
Means and standard deviations of cepstral and spectral measures are provided in Table 3. Results of comparisons among the different mask conditions for each speech task for CPP and L/H ratio were presented in Fig. 3 and Table 3.
Figure 3.
Comparison of L/H ratio values in the normal (A) and patient (B) groups with 3 different speech tasks among 3 different mask conditions (no mask, surgical, and KF94).
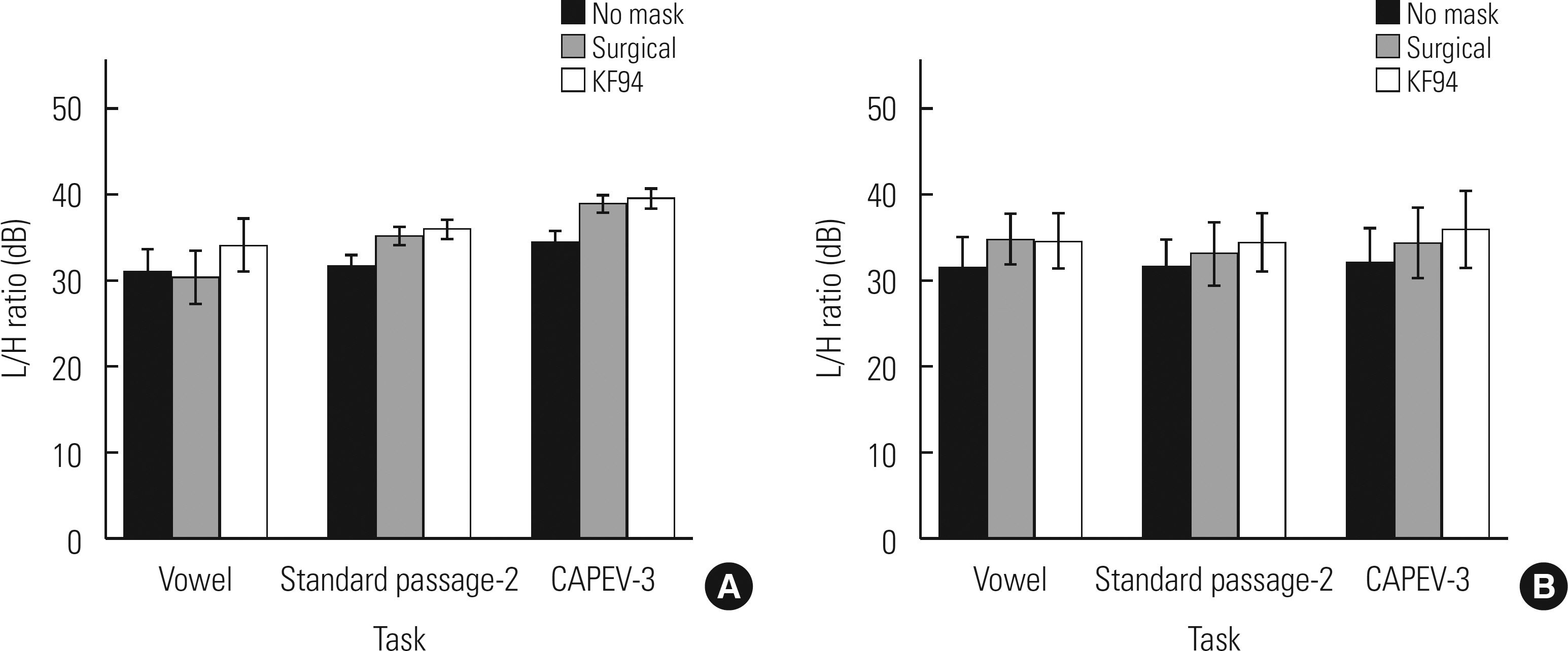
Table 3.
Comparisons of cepstral & spectral acoustic measures for 3 different mask conditions (no mask, surgical, KF94) within each patient and healthy population
One repeated measures ANOVA showed that CPP for the vowel did not significantly change across different mask condition in both healthy (F(2, 38)=1.720, p =0.201) and patient group (F(2, 38)=0.238, p =0.789).
In addition, the CPP for CAPEV-3 also did not significantly differ among the different mask conditions in both healthy and patient groups, while CPP was significantly lower in no-mask condition with CPP-SP2 than wearing face masks in both healthy (p =0.000) and patient group (p =0.006).
Among the cepstral and spectral measures, L/H ratio was significantly lower in no mask condition than mask conditions (surgical or KF94) in all speech tasks in patients.
For vowels, L/H ratio was significantly different in patients (F(2, 28)=20.053, p =0.001). Additionally, L/H ratio significantly differed in standard passage 2nd sentence (F(2, 28) =20.655, p =0.000) and CAPEV-3 (F(2, 28)=38.296, p =0.000).
Similarly, in healthy adults, L/H ratio was significantly lower in no mask condition than mask conditions (surgical or KF94) in all speech tasks (p <0.001).
DISCUSSION AND CONCLUSIONS
The current study investigated the acoustical changes with face mask conditions between patietns with vocal nodules, primary MTD, and adductor spasmodic dysphonia and age-and gender-matched healthy populations.
Traditional time-domain based perturbation measures such as jitter, shimmer and signal-to-noise ratio (SNR) that is required accurate F0 extraction is inadequate for severe dysphonia [27]. Compared to the time-domain based perturbation indices, the quefrency-domain measures such as CPP can be applied to both sustained vowels and connected speech, and ensure the appropriate analysis of disordered voices [11]. In previous studies of healthy speakers, perturbation parameters were measured and in most studies, jitter, shimmer, and CPP values with /a/ vowel showed that there was no significant change with and without wearing a mask and surgical, N95, and cloth masks [9,14,19], while a study demonstrated jitter and shimmer significantly increased with wearing the mask [20], which was consistent with the results of the normal group of the current study during sustained /a/ vowel phonation.
Unlike a healthy adult population, wearing the mask in this study did not significantly impact F0, jitter, shimmer, and NHR compared to without a mask in patients with vocal nodules, MTD, and ADSD in our study. This could be interpreted as the relationship between the vocal intensity and perturbation measures. The parameters jitter and shimmer are widely used in clinical and scientific settings for diagnostic and de-scriptive purposes as well as to document and evaluate voice treatment outcome but vocal intensity had a stronger impact on jitter and shimmer measurements than any other fac-tors[28]. Increased HNR has been found in speakers with increased vocal intensity [29]. In our study, the vocal intensity of vowel phonation in VH group tended to increase when wearing a surgical or a KF94 mask compared to not wearing a face mask, and it can be inferred that the increase in voice intensity affected jitter or shimmer value and resulted in any significant difference for such parameters. These results are pre-sumed that patients with hyperfunctional voice disorders in current study performed more effortful voice production especially during sustained /a/ vowel phonation to compensate for the decrease in vocal intensity while wearing a mask. An-other reason for the discrepancy from the results of other studies may be gender differences due to wearing masks because most of the women were included in this study. This is because vocal nodules, muscular tension disorder, or ADSD are common diseases in women rather than men as etiology characteristics of hyperfunctional voice disorders [4,9].
These findings reflect the role of face mask of the perturbation measures, meaning that clinicians can collect clinical data reliably, irrespective of mask use or mask type when per-forming acoustic perturbation analysis for patients with hyperfunctional dysphonia in voice clinic. Although a previous study revealed that vocal intensity did not change in mask-wearing conditions and all mask condition for sustained /a/ vowel phonation in healthy population [13], the current study showed that there was no significant attenuation of vocal intensity when wearing a mask during sustained /a/ vowel phonation in the VH group. It is assumed that it could be due to the behavior with increased vocal effort adjustment as com-pensation phonation when wearing masks in VH group.
Unlike /a/ vowel, the vocal intensity in healthy and VH groups was significantly attenuated in connected speech when wearing a mask. Some voice and speech signals were changed by wearing a face mask or mask-type mask. For ex-ample, KN95 masks affected acoustic energy at frequencies above 3,000 Hz, and surgical or cotton masks affected frequencies above 5,000 Hz compared to not wearing a mask [4,9]. F94 masks (Korean Standard) usually consist of 3-layers an outer and inner layer or spun-bond polypropylene with higher barrier filtration efficiency like a K95 (US standard) mask which requires tight-fitting hence reducing the trans-mission efficiency of sound [12].
Since the KF94 mask also acts as a low-frequency filter for speech, it reduces the intensity of a speech's frequency in the mid to high-frequency range.
Among the cepstral measures, CPP did not change in all mask conditions for sustained /a/ vowel and CAPEV 3rd (all voiced) sentece, while CPP significantly increased with wearing either a surgical and a KF94 mask in standard passage 2nd sentence (p <0.05) in both healthy and VH groups. L/H ratio was significantly increased during wearing either a surgical mask or a KF94 mask in all speech tasks. Nguyen et al., also [13] found that a significant decrease in mean spectral levels at high frequency regions (1-8 kHz) and an increase in LH1000 when wearing either a surgical mask or a KN95 mask, while sound levels between 2 and 7 kHz was attenuated by 3-4 dB with the surgical mask and by approximately 12 dB with the N95 compared with the non-mask condition in Goldin et al.'s study [7]. This may imply that the face mask also altered the voice signals of hyperfunctional speakers, especially in high frequency.
Overall, in this study, especially during sustained /a/ vowel phonation, wearing a mask or the types of mask did not change the time-based traditional acoustic parameters (jitter, shimmer, and NHR), vocal intensity, and cepstral measures such as CPP while L/H ratio significantly increased during wearing a surgical or a KF94 mask in patients with hyperfunctional voice disorders. This suggests the major acoustic parameters including time-based traditional acoustic parameters and cepstral parameters are valid and reliable when evaluating voice assessment with wearing no mask or both masked conditions for patients with hyperfunctional dysphonia in both /a/ vowel and CAPEV-3rd (all voiced) sentence.
The limitation of this study is a large number of patient and normal groups was not included during COVID-19 pandemic. Nevertheless, it is meaningful in that it directly investigated the effect of wearing a mask on acoustic signals as a prospective study considering the difficult situation of COVID-19. In future studies, it is necessary to prove the results of this study, including various hyperfunctional voice disorders, and the effect of wearing a mask on aerodynamic evaluation, auditory perceptual evaluation, and self-voice evaluation of patients with voice disorders.


