INTRODUCTION
Characteristics of deaf speech
Hearing loss not only causes restricted speech understanding, but also alters speech production resulting in poor intelligibility [1,2]. Due to the loss of auditory monitoring, the articulatory controls of deaf talkers are not regulated by auditory feedback and voice abnormalities in speech are sustained. Numerous studies have reported that the most prominent characteristic of deaf speech is excessive nasality [3,4]. In the beginning, the excessive nasality of deaf speech was thought to be associated with the slow rate of speech typical individuals with hearing loss represent [5]. However, contradictory findings have been reported by Fletcher and Daly [6], and the hyper-nasality has been found to be more related to the abnormal function of velopharyngeal valve caused by cul-de-sac resonance [7]. The cul-de-sac is caused by muffled airflows that block the resonance cavity. Furthermore, speech of the people with hearing loss is typically characterized by labored voice, breathy speech, slow rate, monotonic natures, devoiced stops, and abnormal rhythm [8].
Inadequate vowel articulation caused by nonflexible tongue movement which constricts the pharynx has been assumed to be a primary source of poor intelligibility as well [9]. Acoustic analyses have reported higher fundamental frequencies (F0) in deaf people in comparison with a normal control group [10]. It has been also found that formant frequencies for certain vowels differed between normal hearing (NH) group and deaf group; F2 of vowel /i/ was lower for deaf group [11]. Abnormal speech patterns of hearing impaired (HI) children do not differ greatly from those of HI adults. Liker et al. [12] described a study of Croatian children with cochlear implant (CI) and characterized their speech as having a smaller and frontal vowel space, indistinct frequency distributions between /s/ and /╩ā/, and longer affricates. Uchanski and Geers [13] examined a larger database of acoustic measures (voice onset time, second formant frequency, spectral moments, nasal manner metric, and durations) spoken by young CI users and they found acoustic properties of CI children that are not identical to those by NH children. In addition, they reported that a high percentage of CI children produced acoustic characteristics that are comparable to those produced by children with NH. In summary, the acoustic literature is helpful in understanding the bases of speech abnormalities concerning errors produced by HI talkers.
Spectral moment analysis
Acoustic analysis of deaf speech can be made by examining particular segment of phoneme using various measures. Of the several measures, spectral moment analysis (SMA) is considered as a quantification method that systematically analyze the acoustic characteristics of produced speech in a spectral domain. SMA consists of four primary moments: Mean, Variance, Skewness, and Kurtosis. The spectral Mean refers to the simple average of distributed energy in the spectrum. The second moment, Variance, is the deviation of frequencies represented in the spectrum (the amount of variance in terms of mean). The third moment, Skewness shows the degree to which the amount of energy accumulated at either end of the distribution. Positive (+) indicates higher energy at lower frequency, but negative (ŌłÆ) indicates higher energy at higher frequency. The last moment, Kurtosis, measures peakness of distribution. Higher kurtosis represents thin and peaked distribution, whereas a low kurtosis represents relatively fatty and plat distribution.
Recently, Mendel et al. [14] analyzed four spectral moments (spectral mean, standard deviation, skewness, and kurtosis) for short passages spoken by three hearing impaired groups that were sorted based on perceptual intelligibility. In the results, spectral variance (standard deviation) increased with increases in intelligibility, while kurtosis decreased with increases in intelligibility, suggesting that speech that is more intelligible has a broader range of frequency distribution. Other two spectral moments (spectral mean and skewness) indicated that those with highly intelligible speech yields more energy in the high-frequency. This findings were in line with Raghavendra et al., [15] in which they systematically analyzed the /s/, /╩ā/, /f/, and /╬Ė/ of the same dataset in Mendel et al., [14] by cutting them as a short duration of fricative segments. Another study [16] where Korean fricatives for children with hearing loss were analyzed using SMA reported that spectral mean, standard deviation, and kurtosis were found to be significant indicators showing clinical difference from NH children. They also noted that comparing the alveolar fricatives based on vowels (/a/, /i/, and /u/) do not affect the results.
For the acoustic analysis of speech segment, voice onset time (VOT), F0, F1, F2, duration are typical indexes to be examined in values. However, for the analysis of speech segment where SMA is effectively used is obstruent consonants [17]. Obstruent is yielded by release of noise with either turbulence (fricatives and affricates) or plosive burst (stop). SMA measures and analyzes such noise energy with a statistical procedure using a series of fast Fourier transforms (FFTs). Fricatives are a type of consonant produced by turbulent air flow at pass through narrow opening of oral cavity. Voiceless fricatives can be characterized by its spectral shape according manner and place of articulation. Alveolar sibilant /s/ which shapes a shorter anterior cavity produces higher frequency energies (4 to 5 kHz) compared to the palate-alveolar sibilant /╩ā/, non-sibilant /f/ (labiodental) and ╬Ė (dental) which have relatively flat frequency distribution without dominant peak in any particular frequency. Children tend to have difficulty producing fricatives and produce them at the last stage frequently replacing them with other consonants. CI children have more difficulty producing fricatives than other consonants [13]. This difficulty could probably be caused by articulatory complexity of producing fricatives as well as relatively weaker energy distribution of fricatives in higher frequency range where human auditory system does not handle sensitively.
Purpose
Although many studies on acoustic analysis of speech have examined HI children [16,18], few have examined HI adults particularly using SMA. With a great help of hearing assistive technology, patients with hearing difficulties greatly improved speech as the result of continued use of their devices. Nonetheless, it is frequently reported that these patients still speak with residual speech errors. In this proposed research, we analyzed comprehensive speech data of fricative speech /s/ and /╩ā/ produced by HI adults. We investigated if there is a significant difference in each spectral moment component between NH group and HI group. In addition to SMA, spectral peak and wiener entropy (WE) were also analyzed. Spectral peak detects a particular frequency that has the greatest energy. WE quantifies the spectral density of noise yielding whether acoustic energy is diffused across the frequency or energy is focused at one frequency. It is represented in a log scale, which ranges from 0 (power spectrum is flat) to minus infinity (power spectrum is infinitely narrow).
METHODS
Subjects
The present study was conducted by analyzing deaf corpus data that was obtained at the Speech Perception Assessment Lab (SPAL) at the University of Memphis. Among twenties hearing impaired subjects who have English as a first language in the deaf speech corpus, eight females aged from 22 to 68 (M: 50.62, SD: 13.61 years) were chosen for acoustic analysis of fricatives /s/ and /╩ā/. All of them were bilaterally diagnosed with the severe to profound hearing without history of neurological or cognitive deficits. Six of the participants were wearing either a hearing aid or a CI, but two of them did not use any hearing assistive device. Six of our participants were pre-lingually impaired, but two of them have hearing loss began after critical period of language learning. Table 1 shows demographic of eight HI participants. For the comparison of acoustic characteristics with NH control group, we extracted fricatives of eight normal female talkers from the widely used /aCa/ consonant sets by Shannon et al., [19]. The experimental and control group were those who had no noticeable regional accent.
Acoustic analysis
A set of fricatives /s/ and /╩ā/ spoken by eight females with severe-to-profound hearing loss and NH were taken from the non-sense syllable (aCa) dataset in the deaf speech corpus and in ShannonŌĆÖs consonant data set, respectively. We used Praat program [20] to analyze four major spectral moments (Mean, Variance, Skewness, and Kurtosis), spectral peak (SP) and wiener entropy (WE). First we extracted 40 msec of central position of each fricative from each speakerŌĆÖs /aSa/ and /aSHa/ set. Increasing acoustic energy in high frequency components with a pre-emphasis filter at 80 Hz was carried out. Then, the four SMAs and SP were computed based on the spectral properties in a given 40 ms window of each fricative. For computing the WE, a freely available custom Praat script developed by Gabriel J.L. and Beckers (2004; available online) was used. The procedure of WE analysis is the same, except that WE was estimated without pre-emphasizing high frequency components.
Statistical analysis
Two-way analysis of variance (ANOVA) was performed to determine the effect of groups and fricatives on obtained values. Two groups (NH and HI) and two fricatives (/s/ and /╩ā/) were independent variables assumed to be associated with the products obtained with the set of spectral analysis. Statistically significance level was set as p<0.05.
RESULTS
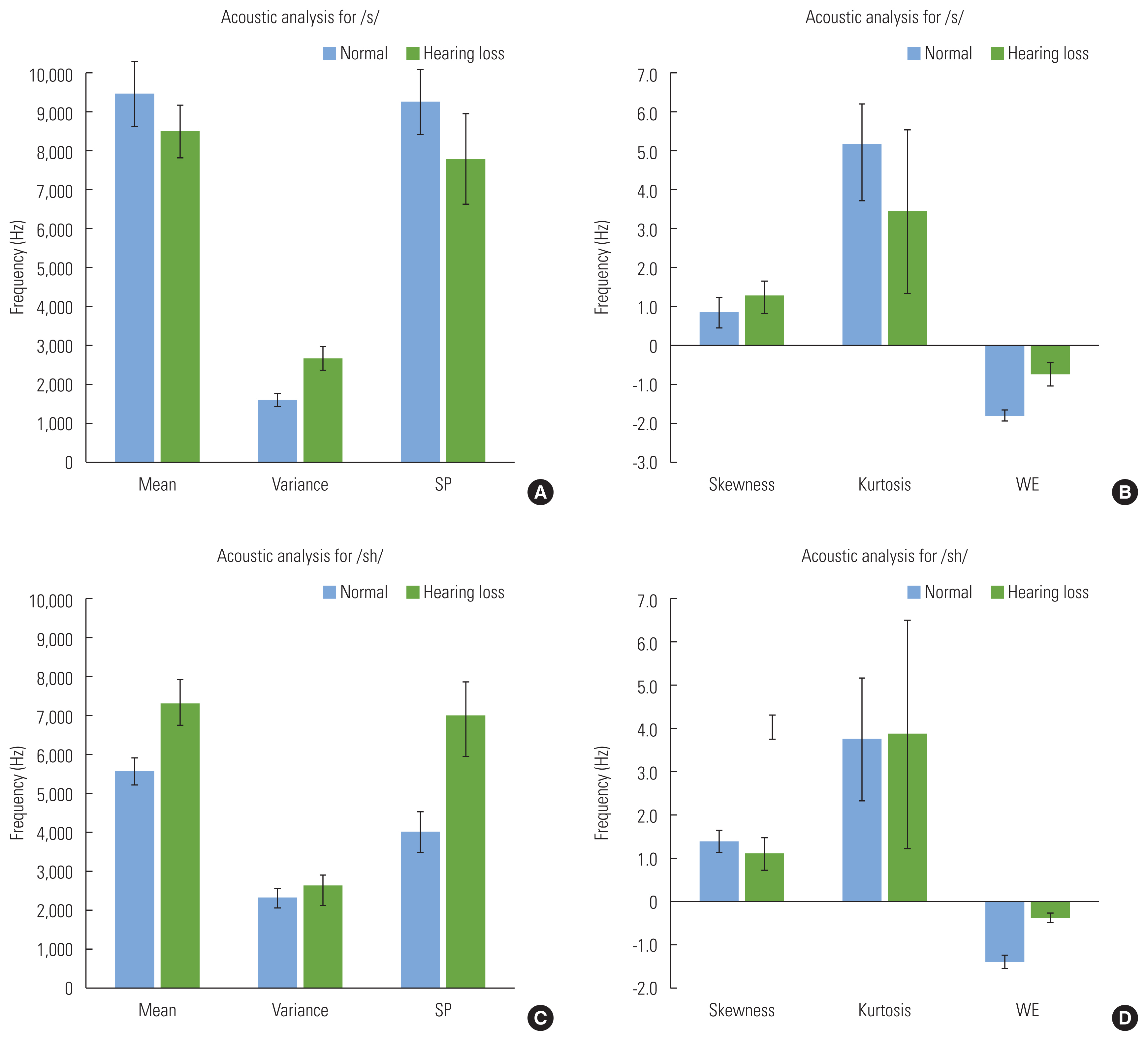
Table 2 shows the group means and standard deviations (SDs) of spectrally analyzed numerical data for /s/ and /╩ā/ spoken by NH and HI groups. It is illustrated in Figure 1: The values of Mean, Variance, and SP were represented in Hz [(A) - /s/ and (C) - /╩ā/], and the other three spectral components, Skewness, Kurtosis, and WE, were derived in small scale units that fall between -2 and 6 [(B) - /s/ and (D) - /╩ā/].
A series of Two-way ANOVAs were conducted that examined the effect of groups and fricatives on each spectral analysis measures (see summary of ANOVA Table 3). Simple main effects of group were found only in Variance and WE outcomes. Variance and WE for HI were significantly higher than those for NH group (p<0.05). There was no significant difference in Mean, SP, Skewness, and Kurtosis between two groups
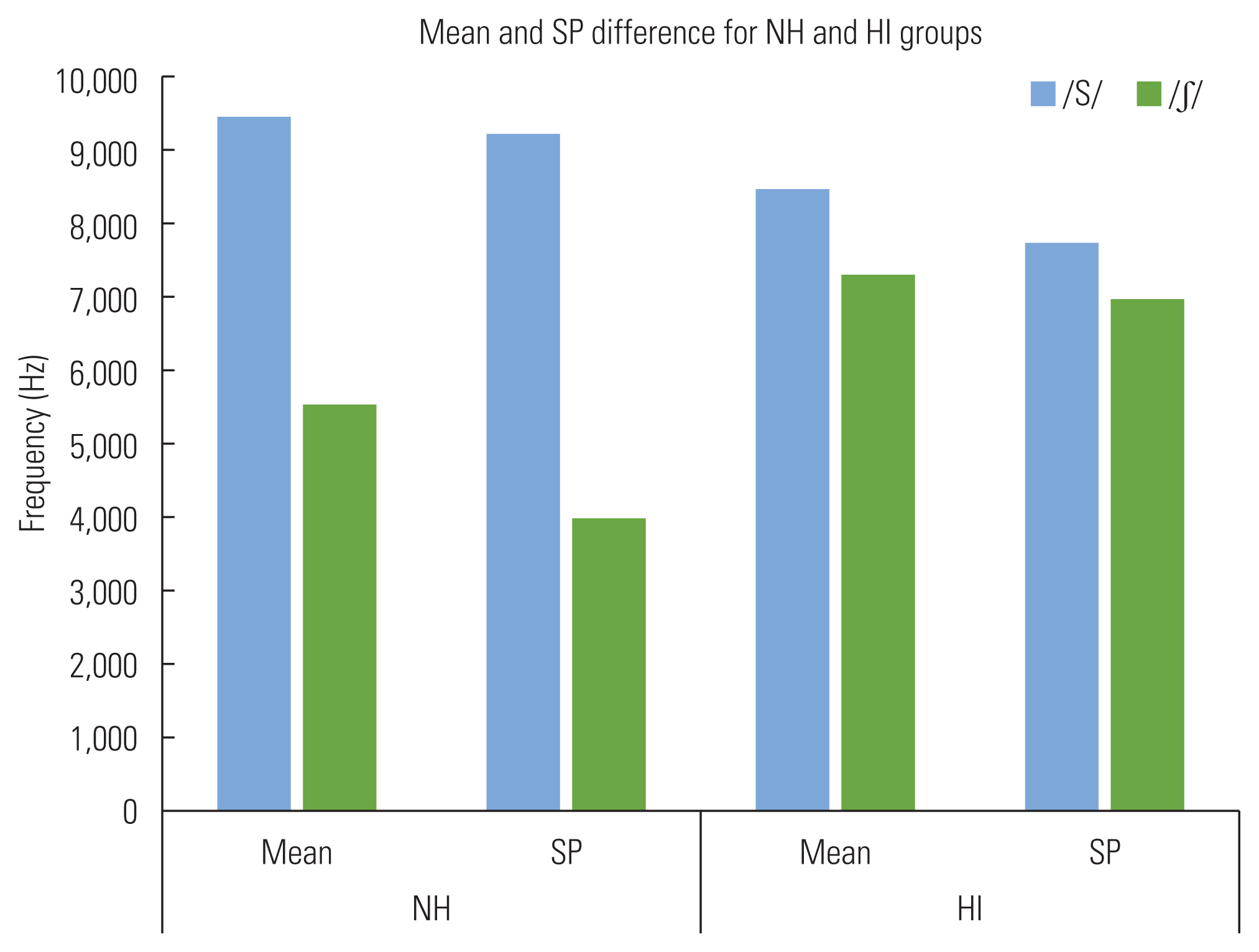
There were significant main effects of fricative in Mean and SP with interaction effects reporting that Mean and SP for /s/ are significantly higher in NH group, while Mean and SP for /╩ā/ are higher in HI group (p<0.05). This trends suggest greater Mean and SP differences between /s/ and /╩ā/ for NH group. On the other hands, there were comparatively smaller Mean and SP differences between /s/ and /╩ā/ for HI group as shown in Figure 2. Another notable result was that the SD of Kurtosis is larger than other spectral measures indicating a greater individual difference in wideness of peak.
DISCUSSION
This study investigated whether English fricatives /s/ and /╩ā/ spoken by people with severe-to-profound hearing loss acoustically differ from those spoken by NH individuals. Acoustic analysis, specifically SMA (Mean, Variance, Skewness, Kurtosis), SP, and WE were used as measures of spectral properties of /s/ and /╩ā/.
Overall, our spectral analysis results were consistent with other literatures that show /s/ has a greater mean, SP, kurtosis, but smaller skewness than /╩ā/ [13,21,22]. Again, the length of anterior cavity determines dominant frequency range of two fricatives /s/ and /╩ā/: Alveolar /s/ produced with a shorter anterior cavity has greater spectral energy at about 4 to 5 kHz, whereas palato-alveolar /╩ā/ has greater spectral energy at 3.5ŌĆō5 kHz. Those spectral measures that segregate /s/ and /╩ā/ were the ones representing frequency regions which contain greater acoustic energy well enough to represent spectral characteristics of fricatives.
A significant Variance and WE difference between two groups was found. There was no other significant difference between two groups. Variance and WE are measures of spectral energy showing how much spectral energy is dispersed across the frequency. Our results suggest that spectral energy of /s/ and /╩ā/ spoken by HI group is more likely to be flat and scattered across a wide range of frequency. It is assumed that unclear and incomplete articulatory movement by HI individuals yielded such fricative energy spread widely rather than focusing at a certain point.
Notably, our finding showed that Mean and SP for /s/ were significantly higher for NH group than HI group, but those for /╩ā/ were significantly higher for HI group than NH group. In other words, the identical pattern was found between Mean and SP. It is reasonable that the first moment of SMA, Mean, is acoustically associated with SP in that they account for at which the greatest spectral energy is located. As shown in Figure 2, the /s/ and /╩ā/ difference in Mean and SP were quite clear for NH group, but not for HI group. Based on this finding, we assume that HI individuals likely pronounce /s/ and /╩ā/ without making clear distinction substituting by each other due probably to the lack of auditory feedback or failure of motor control. The failure of motor control was specified as inability to place a tongue at right vocal position [13]. Although several studies have reported that lower spectra in fricatives (spectral Mean or SP) is negatively related to intelligibility of speech [16,18], our finding indicates that simply higher or lower pitch may not fully explain the different characteristics of deaf speech. This pattern is consistent with Yang et al., [23] where higher SP for /╩ā/ in CI children group over NH group was reported. Acoustic and phonetic analysis are typically carried out in different manner across studies. Some variables, such as the manner of pre-processing, syllable structure, sex and age of speakers may cause the complexity of interpreting results. Thus, intensive care should be taken when comparatively describing the results across the studies.
Despite our effort, some limitations exist in current study. The present study recruited only eight females with the age-unmatched control group data set due to the limited amount of our original data. Thus, the homogeneity of our subjects in our study is unfortunately weak. Although it is not included here, our pilot study found significantly greater Mean and SP for females over males (p<0.05). Another evidence of gender /s/ and /╩ā/ difference has been also previously reported [24]. Thus English fricative /s/ and /╩ā/ spoken by HI males could be different than those spoken by NH male. In addition, our spectral analysis is limited to sibilant /s/ and /╩ā/. Although misarticulation of /s/ and /╩ā/ is one of the common articulation errors that contribute to the speech quality and intelligibility of HI speaker [9], other errors and corresponding analysis also should be included for the better understanding of HI speech. Future studies would be more comprehensive and sophisticated by controlling and considering other important variables with a larger sample size.
Acoustic analyses of the speech by HI talkers have yielded mixed results, with some studies indicating near normal spectral qualities, while other studies have suggested a more pervasive vocal degradation. The results of this study will provide acoustic/phonetic researchers with insight of spectrally distinguishable fricative properties in HI group. With a spectral analysis, quantifying speech intelligibility may be possible. Clinicians including speech therapists could benefit from our findings by using spectral measures as objective indicators for monitoring and examining speech improvement in articulation for HI patients. Moreover, spectral variations in produced speech could be potential cues for prediction speech perception performance. Clarifying the relationship between acoustic properties of deaf speech and their speech perception will be needed in that regard in the future study.