Statistical learning and its consolidation in persons with aphasia
Article information
Abstract
Purpose
The present study aimed to investigate statistical learning abilities and its consolidation in Persons with Aphasia (PWA).
Methods
Ten PWA following stroke and Ten Neuro-Typical Individuals (NTI) were recruited for the study. Serial Reaction Time Task (SRTT) was used in the study. Sequence and random pattern blocks were used within the paradigm. The task was administered in three sessions, learning session (day 1), second session (24 hours after learning session), and third session (two days after the second session). In the third session, a recall block was introduced. Reaction time served as the outcome measure from the task administered.
Results
The results revealed that NTI outpaced the PWA in learning from SRTT. A statistically significant difference was found (p<0.05) for sequence patterns between groups measured across three sessions, but it was not the same for random patterns. Index of sequence learning was derived, and no significant effect (p>0.05) was found on Mixed ANOVA. Consolidation of learning between groups was analyzed using an Independent t-test for the second session and third sessions. It was found a significant difference between groups for the second session but not for the third session. A significant difference (p<0.05) between groups was found for recall scores.
Conclusions
According to the study’s results, even though PWA did not perform at the level of NTI in all measures, PWA demonstrated learning, and its memory traces were consolidated. Retention of learning was observed even though it was learned implicitly. PWAs were able to recall the implicitly acquired information explicitly.
INTRODUCTION
Learning is the process of acquiring knowledge about skills and behaviors through exposure to environmental stimuli. Learning can take place in two ways: explicitly and implicitly [1]. To learn a behavior, explicit learning necessitates awareness and attention. On the other hand, implicit learning occurs without the use of attention, consciousness, or knowledge of the behavior’s properties [2,3]. After multiple exposures to a stimulus, implicit learning occurs. Implicit learning is assumed to happen without placing any demands on attention and working memory mechanisms. Implicit learning has various forms of learning, namely priming, category learning, artificial grammar learning, and statistical learning. Statistical learning is the paradigmatic measure of implicit learning. Implicit learning is interchangeably termed and used as statistical learning or implicit statistical learning. The product of statistical learning is implicit knowledge, which is intuitive, tacit, and procedural. The statistical learning knowledge cannot be reported or explained because it exists in the form of statistical regularities, which are connections between memory nodes, and these regularities can only be manifested in actual use.
Learning not only occur during the task, i.e., online-periods but also between the online-periods, i.e., called offline-periods. Offline periods are the time where there is no active practice or task goes on. Offline periods are the periods where the learned skill gets enhanced and termed as consolidation. In other words, consolidation is a process of enhancing and stabilizing the memory traces of the initial learning/acquisition. It results in a stabilized or improved performance [4–6].
Consolidation or offline changes depend on the factors like form of learning, information type in the learning, and participants’ age. The learned skill that gets consolidated depends on the post-learning phase’s time course to stabilize the memory traces. This period can vary from 1 to 2 hours [7], to 5 hours [8, 9], 6 hours [10], 12 or 24 hours after sleep. Consolidation of newly learned skill memories will be more significant over sleep-intervals. Consolidation processes may be due to cortical reactivation [11], corticothalamic plasticity, and sleep spindles [12–15].
There are convincing shreds of evidence that the memories gathered from both forms of learning get enhanced over sleep time. Studies have assessed learning on explicit and implicit conditions in the typical children and adult population [16–19]. The focus of the present study is mainly on learning under implicit conditions. The retention of a learned skill is most remarkable in younger adults, and many studies have confirmed the findings. However, the same trend is not observed in older adults. The studies [20,21] have shown that memory consolidation results are preserved in older adults, but it is reduced compared to younger adults.
Using Serial Reaction Time Task (SRTT), a study [22] concluded that consolidation of learned skill after the initial session was directly proportional to the length of the delay. It was observed that enhancement in learning was observed in a retention session that took place 4 hours and 12 hours after the initial session but not after 2 hours. In this study, skill consolidation was observed only up to 12-hour intervals. Another study [20] investigated skill consolidation after 24 hours of the initial learning session. Younger adults performed significantly better than older adults, and performance on retention sessions held 24 hours after the training session improved the task. Even though older adults’ performance was improved in the retention session, researchers were unclear to attribute the reasons for the preserved consolidation effects in them.
The study of skill consolidation after 24 hours from the initial learning session is an intriguing memory consolidation process. To address this, a study [21] used the Alternating Serial Reaction Time (ASRT) task to investigate implicit statistical learning and its consolidation in young and older adults, dividing them into three groups based on the retention session schedule, i.e., 12 hours, 24 hours, and 1-week post initial learning session. The number of blocks used within the ASRT task was 25 in the learning session and five in the retention session. Based on the sequence structure, learning was assessed as general skill learning and sequence-specific learning. It was found that young adults in all delay conditions showed improvement with regard to general skill learning. However, older adults displayed improvement in general skills but only in 12-hour delay conditions. Concerning sequence-specific learning, no group showed improvement in any of the consolidation intervals. These results concluded that young and older adults would demonstrate similar learning levels in the first session and resistance in memory until 12 hours, but post 12-hour intervals, and older adults showed decreased consolidated performance.
It is essential to extend the research from normal to the disordered population to understand the mechanism’s nature. Consolidation of statistical learning has been studied in very few disordered population. Aphasia is one of the adult neuro-linguistic conditions, mainly due to stroke, TBI, and other causes. It is cardinal to discuss the learning and its outcomes in aphasia, as it involves abnormal brain processes due to neurological changes. Many studies have been carried out regarding statistical learning in Persons with Aphasia (PWA) using different tasks in both implicit and explicit conditions. In SRTT, people with agrammatic aphasia showed statistical learning of sequences [18,23,24], but they also had difficulty learning certain types of sequences [23] and learning abstract underlying structures of sequences [25].
Consolidation of learning in PWA has been investigated in very few studies. A study [26] investigated statistical learning using SRTT in three groups (four participants followed unilateral stroke) in each group. The extended practice for three days with no explicit information regarding the task to the first group, the second group received explicit information but received no extended practice and the third group with no explicit information and no extended practice. The group with extended practice did not show improved performance. Recall and recognition of sequence were only demonstrated by participants who had received explicit information regarding the task. Another study [27] looked at SRTT learning in implicit and explicit conditions. In this study, participants were divided into two groups (Explicit Information (EI) and Non-EI group) within normal and clinical groups. A total of 30 participants, 20 in the clinical group (Ten participants with basal ganglia and sensorimotor cortex stroke were in the clinical group and ten in the normals group). A 10-element sequence, which included colors as stimuli appearing on the computer display screen, was presented in order (random, sequence, random, and sequence block) for three consecutive days. For the EI group, progressively explicit information regarding the task was given. It was found that participants with the stroke of the non-EI group had better performance on SRTT at the end of day three and retention test compared to participants with the stroke of the EI group. The normal group had significantly better performance than the clinical group. In both studies, explicit knowledge was assessed using subjective awareness, recall, and sequence recognition. Only the EI group had awareness and was low in recall and recognition of sequence in both clinical and normal groups.
In a retention session held 24 hours after the initial session, participants with stroke showed retrieval of knowledge about the sequence [28]. A study [24] investigated statistical learning and grammar learning as a two-fold experiment in nine PWA and 21 healthy adults. In experiment one, SRTT was used. In experiment two, as a part of grammar learning, participants were made to listen to the sentences (consisting of pseudowords designed using phrase structure grammar) for 30 minutes and followed by a sentence judgment task. The same procedure was repeated the next day for both groups. From the study, it was observed that both groups performed equally in the SRTT paradigm.
In the earlier studies, retention of learning was assessed within few days of the learning session. However, a study [29] extended the investigation of assessing learning retention after two weeks of the initial session. A total of seven participants with stroke and nine normals were included in the study. SRTT was used, a total of 54 blocks were programmed in the paradigm. Two days of learning session were carried out, and the third session was held after two weeks from the second session. In the third session, retention, generation, and transfer of learning were assessed. Both the groups exhibited initial learning, and particularly participants with stroke retained knowledge even after two weeks. They also exhibited the transfer of knowledge from the current task to the other similar topographical task.
Need for the study
The purpose of this study was to investigate statistical learning processes in PWA by addressing the concerns posed from the previous studies, such as the consolidation of learning, schedule of retention session, number of trials, number of elements in the sequence, and response mode in the SRTT paradigm [23,26,29].
In this study, the SRTT paradigm was chosen over the other paradigms because it is a well-established paradigm that does not require any linguistic processing. Participants with language impairments could complete the task [24], particularly PWA. Although the SRTT stimulus structure is simpler than the language’s grammatical rules, the ability to learn the patterns in the SRTT is related to language processing abilities, specifically the ability to predict upcoming words in a stream of speech or sentence [25,30,31]. SRTT has been used to identify learning difficulties associated with clinical conditions such as specific language impairment [32–34] and dyslexia [35,36].
Studies have put forth efforts to explore the statistical learning abilities in PWA. However, only a few studies in the literature have looked at learning consolidation in PWA. Consolidation and reconsolidation of statistical learning are not studied systematically, considering the time post-initial session and number of trials [21] across PWA sessions. The process of reconsolidation is a debatable and interesting one that is not much explored. It becomes imperative to study PWA’s consolidation and reconsolidation process due to the brain’s recent and ongoing neurological changes.
As most PWAs have poor motor skills, using key presses or mouse clicks as a response mode would be difficult. Hence, the present experimental design deployed a touch screen as a response mode in the task. Further, using a spatial version of SRTT would provide a better picture of learning in the visuospatial domain. The difference in performance between standard groups from the central version of SRTT is considered less significant than the difference in performance between standard groups from the spatial version of SRTT [37].
Another vital aspect that strengthens the study’s need is that most research on the statistical learning process has been conducted in the Western context. Only two studies in the Indian context have been published in the clinical population, i.e., in individuals with specific language impairment. The cultural variation exists between Westerners and Southwest-Asians, accounting for differences in cognitive processing [38]. As a result, it was essential to research in the Indian context to validate previous findings. Hence, the present study was carried out to investigate research gaps in statistical learning and its consolidation in PWA.
METHODS
Participants
The study enrolled ten PWA who had previously suffered a stroke. PWA with a score of 100 or higher on the Auditory Comprehension section of the Western Aphasia Battery-Kannada [39] and scores greater than or equal to 24 on the Mini-Mental State Examination (MMSE) [40] were only recruited. Additionally, participants with enough motor ability to respond on the laptop (right-handedness) and normal or corrected to normal vision and hearing were included (Table 1).

Demographic details about the study’s participants (clinical group)
The ten Neuro-Typical Individuals (NTI) recruited were PWA caregivers or family members to match both groups in terms of communication background and socioeconomic status. Individuals with no sensory, developmental, learning, or neurological deficits were selected for the NTI group.
Participants from both the groups were native speakers of the Kannada language (a South Indian Language) and a minimum 10th grade of formal education. Before their participation, informed written consent was obtained. The present study followed AIISH ethical guidelines during the recruitment of participants and the data collection process.
Materials
SRTT, a standard variant, was used in the experiment. An eight-item sequenced pattern was used in this task instead of a 10 or 12 element sequence (used in the earlier research studies). The use of more elements in a pattern requires more time and may result in fatigue in PWA. In this task, a vehicle picture was used as a stimulus. Vehicle picture appearing in one of the four quadrants on the display screen with a predetermined unbeknownst pattern (an eight-sequence pattern – 42313214 – here 1 corresponding to the left-most square and 4 corresponding to the right-most square). The pattern was presented in 10 trials. Hence, there were a total of 80 touch-presses in the sequence pattern block. In a random pattern, there were 60 elements, which equals 60 touch-presses (23141234... 31421243...). The task begun with the practice trials and followed by the patterns in this order (random pattern (R1)-sequence pattern(S1)-random pattern(R2)-sequence pattern (S2)). The task was designed and programmed using Psychopy software – version 1.83 [41] and fed into a laptop (Lenovo Yoga-touchscreen, screen width-13 inches). The task was presented to the participants by placing the laptop in a folded position (360 degrees).
Assessment of learning consolidation and reconsolidation, the task was introduced 24 hours after the initial session (the number of trials was reduced to 8 trials in sequence and random pattern) and three days of the initial session (the number of trials was reduced to 4 trials). In the third session, participants were tested for recalling the sequence (this block was called as a recall block that included six trials, 12 points in the block were missing randomly, and the participants were expected to identify/predict them).
Procedure
Participants were seated infront of the laptop in a room void of sounds and visual distractions. They were asked to provide responses using their preferred hand. Task involved practice trials before the test trials to facilitate acclimatization. Adequate rest was given after each block as required to the participants.
The participants were instructed to look for the vehicle picture in one of the four quadrants on the laptop display screen. When the picture appeared on the laptop display screen, participants responded by touching the screen against the picture (appear in one of the quadrants on the display screen) as quickly as possible. No information was given about the underlying pattern or instructions to learn the pattern. Concerning the recall block, participants were asked to predict the missing location in the course of the task continuum to assess whether the participants can explicitly recall the implicit knowledge acquired through implicit form of learning.
Analysis
Reaction time (RT) and accuracy measures were the dependent variables of the present study. The RT was calculated in milliseconds (ms) for each trial, which is the time between the appearance of the stimulus and the response press/touch. It is assumed that the participant’s RT will get faster after a certain number of trials in the sequence pattern phase. However, in a random pattern, RT will be slower when compared to the sequence phase. Random and pattern sequence phases were included to differentiate the learning that is particular to the stimuli’ sequence pattern.
The performance on SRTT was measured using two measures: general learning and specific learning. Furthermore, the course of learning within a session, as well as consolidation and retention of learning, were explored. In this paradigm, learning was designated by higher RTs in the random block compared to the sequence block. A simple method of measuring the learning was by computing the gradual RT that takes place across the sequence trials is called general learning. This measure provides information about the participant’s growing command in task performance. Additionally, it gives details about the association between the visuo-spatial cue and expected response. Thus, a change in sequential RT provides a standard measure of participant’s aptitude at performing the SRTT.
In addition, to track the course of learning within a session, the RT on the sequence trials were averaged at four different points in both patterned blocks and random blocks to trace the course of learning [42]. The RT of the patterned sequence was taken averages from both block one and block two. The two interims were average of block one trials sets of 3, 4, and 5 noted as patterned sequence average 1 (B1SP1) and trial sets of 8, 9, and 10 as patterned sequence average 2 (B1SP2). Other interims from block 2 were from trial sets of 3, 4, and 5 noted as patterned sequence average 1 (B2SP1) and trial sets of 8, 9, and 10 as patterned sequence average 2 (B2SP2). It was calculated only for the learning session in both groups (Figure 1).

The measure used to track learning in the first session.
Another measure derived from the pattern and random sequence RTs difference is called sequence-specific learning, and it was measured for all three days/sessions (D1, D2 & D3). This measure is considered as a complementary measure to general learning. When a random pattern replaces a sequence pattern, the sequence pattern’s learning is disrupted, and the random pattern’s RT is inflated. This measure delineates the possible influence of motivation and fatigue factors from actual learning. The final values demonstrate the presence and effectiveness of sequence learning. It is termed as Index of Sequence Learning (ISL), calculated by subtracting from averages of random sequence sets to pattern sequence sets (Figure 2). The formula for the Index of sequence learning is generated on an empirical basis [43–45]. It suggests that sequence learning on sequence trials would be significantly better after adequate successive trials than random trials [44,46]. In the SRTT, the ISL was used to index procedural sequence learning [42,52,53]. The ISL measure was calculated for all three sessions and both groups.

Formula used to calculate Index of learning.
Consolidation of learning was tested by comparing the RTs between the sequential second block of session one and the sequential first block of session two, which is called as C1. To check the consolidation of learning from the 2nd session to the 3rd session, RTs were compared between the sequential pattern of the 2nd block of session 2 and the sequential pattern of the first block of session 3, called as C2.
The recall block presented in the third session, a score of 1 for each correct recall of the location, and the total score is 12. It involved 12 points for prediction out of 48 points in that block.
RESULTS & DISCUSSION
The current research used the SRTT paradigm to investigate statistical learning and its consolidation in PWA and NTI. In SRTT, accuracy and reaction time measures were calculated for each block. Throughout the experiment, response accuracy remained very high (average of more than 97 percent for both groups) [21,24]. Hence, the accuracy measure was not subjected to further analysis. The performance on SRTT was assessed using two measures, i.e., general learning and specific learning. In addition, the course of learning within a session and consolidation and retention of learning was analyzed. The data gathered from the study’s task was subjected to statistical analysis using IBM Statistical Package for Social Science (SPSS) for Windows, version 20.0, (IBM Corp., Released 2011, Armonk, NY, USA). Effect size criteria considered in this study to analyse the true significance were small effect, ηp2=0.01 [<0.06]; medium effect, ηp2=0.06 [≥0.06 to <0.14]; and large effect, ηp2=0.14 [≥0.14] [54]. Likewise, the effect size for a non-parametric test, i.e., Correlation coefficient (r), was determined by dividing the Z value by the square root of the sample size. In this analysis, the interpretation values for r were: 0.1 to 0.3 for a small effect, 0.3 to 0.5 for a medium effect, and 0.5 for a large effect [55].
The current study’s findings are presented under the following headings: (a) to compare course of learning in the initial session between PWA and NTI; (b) to compare general learning in SRTT across sessions in PWA and NTI; (c) to compare specific skill learning in SRTT across sessions in PWA and NTI, and (d) consolidation of learning in SRTT in PWA and NTI.
a) Comparison of course of learning performance in initial learning session in PWA and NTI
In SRTT, reaction time were calculated for each block. To track the course of learning in the task within a single session, learning was measured in the initial session only for sequence pattern blocks. The descriptive statistics data are given in Table 2.

RT of two interims of Block 1 and Block 2 in PWA and NTI
The mean RT values were lower in the NTI group than their counterparts, indicating faster responses to stimuli. By inspecting the minimum and maximum values from Table 2, it was possible to conclude that there was only a marginal difference in the minimum value between PWA and NTI. However, there is a substantial difference in maximum values between PWA and NTI. PWA had higher maximum RT values indicating they were slow while reacting to the stimuli in the SRTT. A pattern can be seen in the maximum values from blocks 1 and 2, indicating that the RT upper limit decreased over time and in trials, which was only observed in the NTI group (Table 2).
Furthermore, the data were subjected to a normality test, the Shapiro-Wilk test, which showed that it was not normally distributed (p<0.05). As a result, a non-parametric test named the Mann-Whitney U test was utilized to validate the difference in performance based on RT calculated for two averaged trials of block 1 and block 2 between PWA and NTI groups. A statistically significant difference for B1SP1, B1SP2, B2SP1 and B2SP2 (|z|=2.19, p<0.05, r=0.69) were found with large effect size [54] between PWA and NTI groups. Consequently, the two interims measured within the blocks 1 and 2 were separately analyzed using Wilcoxon signed-rank test in PWA and NTI group. It was found that no significant difference between two interims (B1SP1 vs. B1SP2) (|z|=0.51, p>0.05, r=0.11) of block 1 and (B2SP1 vs. B2SP2) (|z|=1.37, p>0.05, r=0.30) block 2 in PWA and (B1SP1 vs. B1SP2) (|z|=0.76, p>0.05, r=0.17) of block 1 and (B2SP1 vs. B2SP2) (|z|=0.45, p>0.05, r=0.10) in NTI group.
It was assumed that learning gets better with trials, i.e., from block 1 to block 2 (progress in learning, i.e., reduction in RT) within a session. Hence, it was measured at two interims within each block to trace the course of learning. However, the reduction in RT from interims within blocks 1 and 2 in NTI was noticed on visual inspection (Figure 3), but no statistically significant difference was observed (p>0.05). On the other hand, PWA showed a pattern of progression and regression in the performance. This may be explained by reactive inhibition, decreasing non-reinforced motor performance after several trials [47]. Using adapted-SRTT, similar findings have been reported in typically developing children [42]. Based on mean RT values on this metric, the NTI group outpaced the PWA group substantially faster.
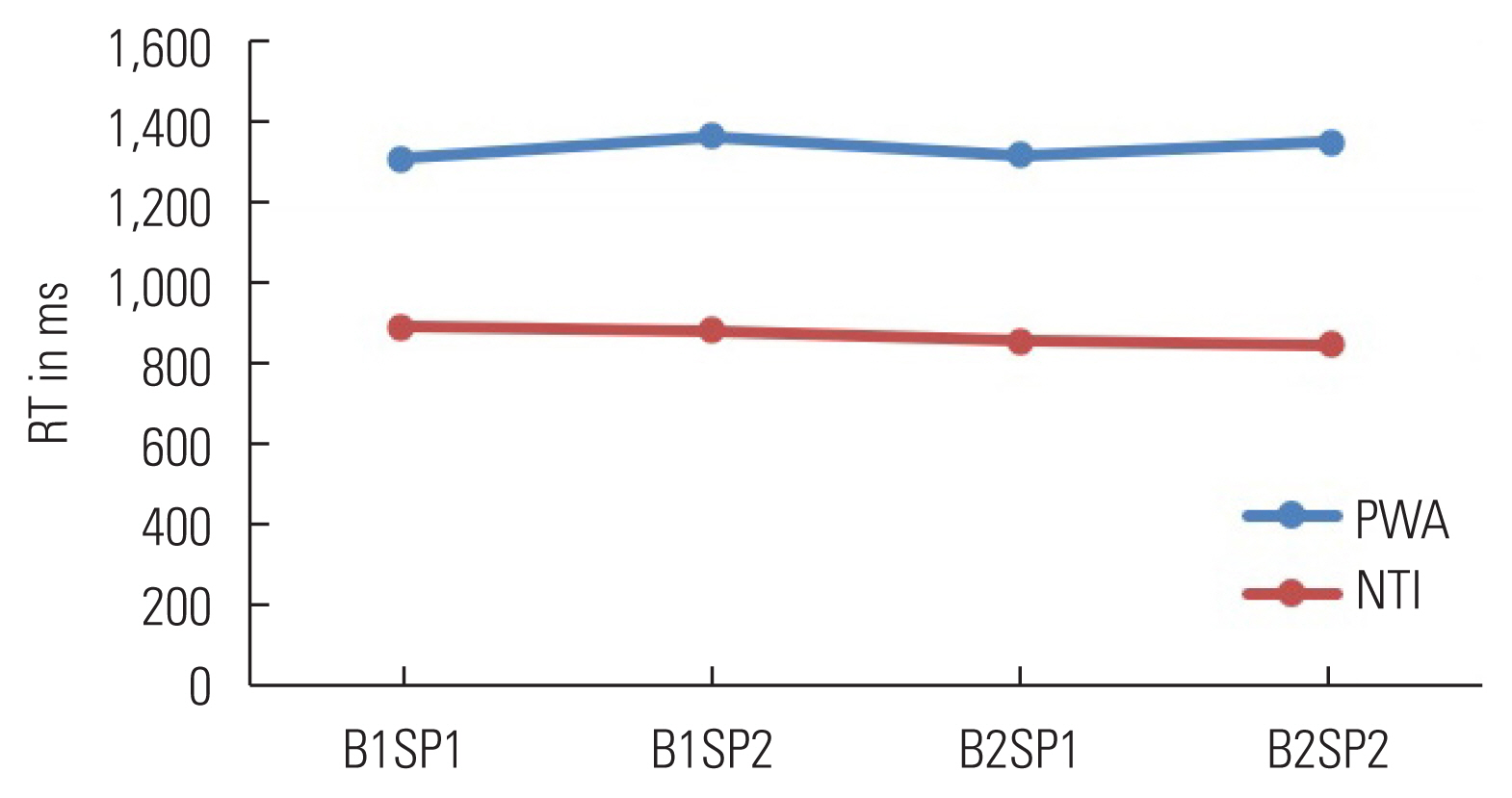
Comparison of learning over the trials within block1 and block2 among two groups. PWA, persons with aphasia; NTI, neurotypical individuals; B1SP1, block1 sequential pattern 1; B1SP2, block1 sequential pattern 2; B2SP1, block2 sequential pattern 1; B2SP2, block2 sequential pattern 2.
b) To compare general learning in SRTT across sessions in PWA and NTI
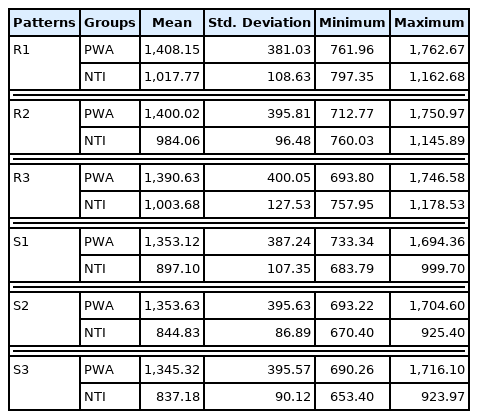
General skill learning was tested by comparing the overall RTs of sequence pattern and random pattern of block 1 of all three days in PWA and NTI using descriptive statistics (Table 3). When the mean RTs of random and sequence patterns were compared, the mean RTs of sequence patterns were lower. When comparing the groups, PWA had higher mean RTs and standard deviation values, suggesting slower responses and greater variance. On visual inspection, no differences in mean RTs of both random and sequence patterns were observed across sessions in both the PWA and NTI classes (Figure 4). While there were no variations in the minimum RT value in random and sequence patterns in both the PWA and NTI groups, the maximum RT value differed significantly between the groups.
RTs of Patterns (general learning) across day 1-2-3 in PWA and NTI
Comparison of learning over the random and sequence patterns across sessions in PWA and NTI. PWA, persons with aphasia; NTI, neurotypical individuals; S1, sequential pattern of day 1; S2, sequential pattern of day 2; S3, sequential pattern of day 3; R1, random pattern of day 1; R2, random pattern of day 2; R3, random pattern of day 3.
The data were subjected to a normality test (Shapiro-Wilk test), which showed that it was not normally distributed (p< 0.05). As a result, non-parametric tests were used. Sequence pattern RTs of day 1, day 2, and day 3 were compared between PWA and NTI using Mann-Whitney U test and a significant difference was found for S1 (|z|=2.19, p<0.05, r=0.69), S2 (|z|=2.49, p<0.05, r=0.78), S3 (|z|=2.45, p<0.05, r=0.77) with large effect size. For random patterns, no significant difference was found for R1, R2, and R3 (|z|=1.81, p>0.05, r=0.57), but a large effect size was found. To see the difference between RTs of sequence (S1, S2, S3) and random pattern (R1, R2, R3) within PWA and NTI using Friedman test. It was found that no significant difference in both groups (p>0.05).
The NTI group outperformed PWA on all three days of sequence pattern learning, and it is consistent with earlier study findings [27], and contradicting findings were also found [24]. Furthermore, after three days of learning on a random pattern, no difference was observed between PWA and NTI [27]. Overall, mean RTs for the sequence pattern were lower across all days than the random pattern, indicating that learning that occurred in the sequence pattern demonstrates that participants learned based on the sequential knowledge present between the dependencies that was available in the sequence pattern, despite the fact that the learning session was in the implicit condition [27,42,44,46].
c) To compare specific skill learning of SRTT across sessions in PWA and NTI
Specific skill learning of SRTT was computed using the formula which is described in Figure 2. The derived values were subjected to statistics. The descriptive statistics of ISL for both PWA and NTI across sessions are given in Table 4. Higher ISL values indicate better learning. It was observed that lower mean ISL values across all sessions in PWA compared to NTI indicated poorer learning.

Specific skill learning of SRTT in PWA and NTI
The data were subjected to a normality test (Shapiro-Wilk test), and it was found to be normally distributed (p>0.05). Hence, the parametric test was used. Mixed ANOVA was performed to see the difference between ISL measures across the sessions and groups. There was no significant effect of ISL measures [F(2,36)=0.74, p=0.48, ηp2=0.04] with small effect size. Further, no significant interaction effect between specific skill learning and group was found, [F(2, 36)=0.99, p=0.38, ηp2=0.05] with small effect size. There was a significant effect of the group, indicating both PWA and NTI had a difference in skill learning [F(1, 18)=53.6, p=0.00, ηp2=0.74] with large significant effect size. Based on a pairwise comparison of possible pairs (ISL1 vs. ISL2 vs. ISL3), it was found no significant difference in any of the pairs (p>0.05).
From the mean values of ISL measure across all three days, it could be noted that NTI was better than PWA, indicating that NTI was better in learning (Figure 5). This was supported by a study [33,45] that clinical groups are not effective in learning than NTI based on ISL measures derived from SRTT. There was difference in the derived values of ISL measure across the sessions in both groups, indicating no improvement in learning across the session.
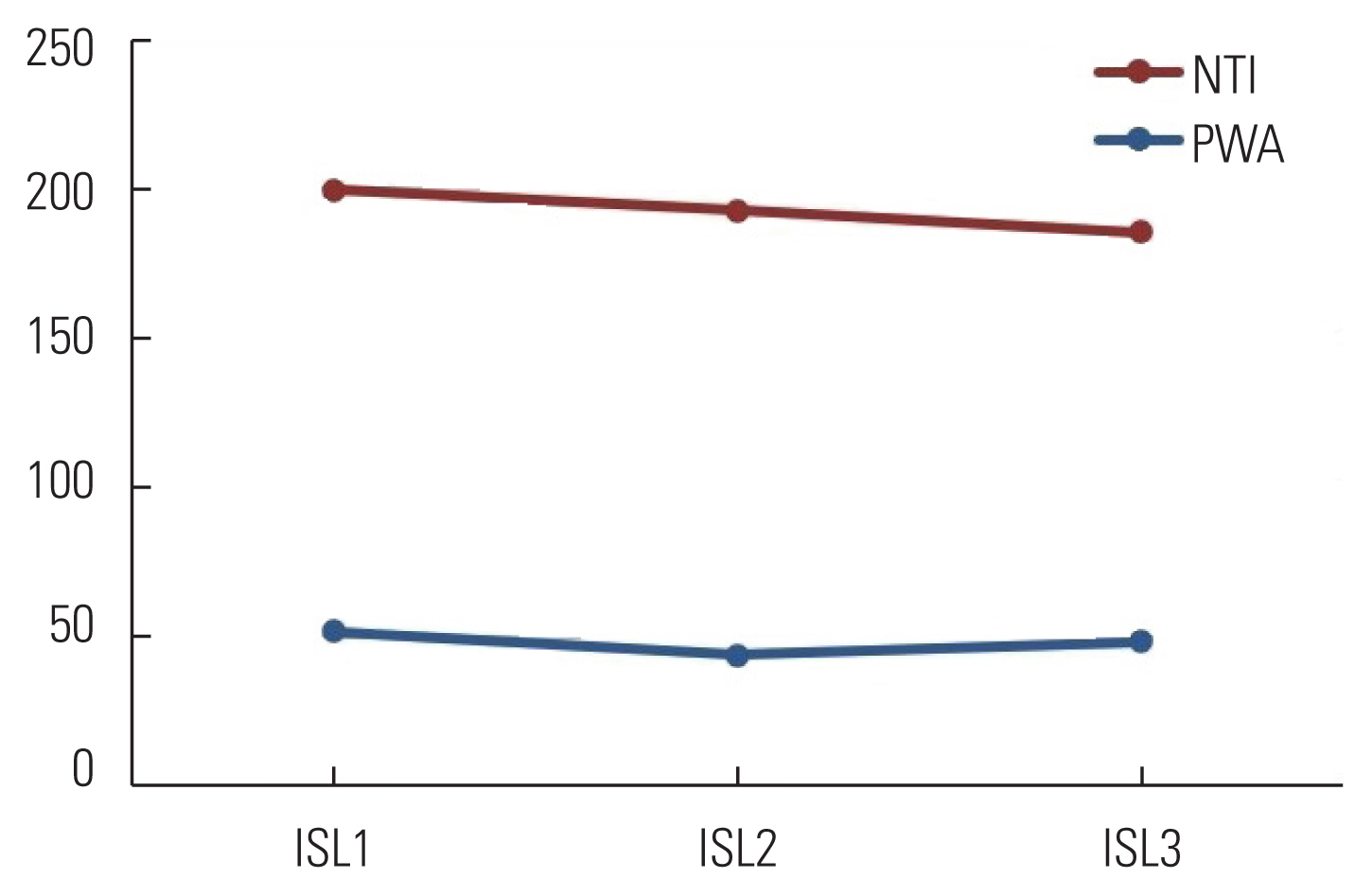
Comparison of ISL measure across sessions in PWA and NTI. PWA, persons with aphasia; NTI, neurotypical individuals; ISL1, index of sequence learning of day 1; ISL2, index of sequence learning of day 2; ISL3, index of sequence learning of day 3.
d) Consolidation of learning in SRTT in PWA and NTI
Consolidation of learning was tested in both PWA and NTI groups. The data derived from the analysis were subjected to a normality test. It was found that data was normally distributed based on the Shapiro-Wilk test (p>0.05). To compare this across two groups, i.e., PWA vs. NTI, an Independent t-test was used. On average, NTI had better consolidation of learning in C1 (M=14.42, SE=9.29) compared to PWA (M= −24.35, SE=8.51) and significant difference was found (t(18)= −3.07, p=0.006, r=0.58) with large effect size. For C2, PWA had better consolidation of learning (M=7.63, SE=13.20) compared to NTI (M=−5.80, SE=7.98), but this difference was not significant with small effect size [t(18)=0.87, p>0.35, r=0.2].
On the retention sessions, the learning was consolidated in both groups. NTI had better consolidated performance than PWA in the second session, but NTI group consolidation of learning was lower in the third session. On the other hand, PWA had a better consolidated performance on the third day than on the second. This result was supported by other study findings [27–29]. Though, the number of elements used in the sequence pattern was lower compared to previous studies to overcome fatigue in PWA, the researcher expected substantial consolidation of learned information due to the simpler pattern being implicitly learned. Since no substantial consolidation occurred in NTI and PWA compared to earlier study outcomes, it can be assumed that the nature and length of the stimuli present in SRTT have no effect on learning and its consolidation.
The performance on recall block, the performance between PWA and NTI was compared. Descriptive data are given in the table. The data were subjected to a normality test, namely the Shapiro-Wilk test, and it was found that it is normally distributed (p>0.05). Further, an independent t-test was used to analyze the difference between the two groups. It was found that NTI had better scores on recall block (M=4.80, SE=0.20) compared to PWA (M=2.20, SE=80.41) and significant difference was found (t(18)=4.64, p<0.05, r=0.73) with large effect size.
On visual inspection, it can be noted that both the groups were able to predict the element of the sequence maximum of 50%. PWA group had poorer performance than NTI, but they could recall with the available amount of knowledge gained implicitly. This is in consensus with earlier study findings [29]. The present results contrast with study findings [27], where only groups with explicit information about the task before training exhibited recall, recognition, and awareness about the sequence.
The current study aimed to assess statistical learning mechanisms in PWA aftermath of stroke incident. The current study’s findings demonstrated learning in PWA, the durability of this learning over time. Learning was evidenced by a substantial decrease in RTs across trials for the SRTT’s sequence pattern blocks, coupled with a significant increase in RTs in the random pattern blocks. In addition, PWAs were able to recall elements from the sequence on the third day. Learning got better in the third session than the second session in PWA, which indicates the presence of consolidation and reconsolidation of memory traces. The use of novel response mode (touch screen mode) and the spatial version of SRTT did not lead to any new findings than earlier experimental design.
Overall, implicit statistical learning mechanisms are maintained in stroke induced PWA, supporting previous studies that found limited in learning on the SRTT compared to NTI [23,48–51]. Also, this study’s findings contradict the results of other researchers, who claim that even after prolonged practice, implicit statistical learning is impaired after stroke. Learning is only observed when participants have explicit knowledge of the repeated sequence before performing the SRTT [26,27].
CONCLUSIONS
The current research attempted to investigate statistical learning processes in PWA following a stroke event. The study’s results illustrated learning in PWA and the persistence of this learning over time. Although this study’s findings support the past research, a degree of caution should be exercised before expanding these results directly into the general PWA population. Several factors restrict the findings’ generalizability. Since no imaging data were available for the limited recruited sample population, it was difficult to draw firm conclusions about (1) the effect of right versus left hemisphere lesion on learning and (2) extending the results to all other types of implicit learning, (3) generalizing the consolidation intervals set in the present study as a schedule during learning/training.
Future research could compare statistical learning in stroke vs. TBI-induced PWA, considering the brain’s focal and diffused lesion pattern. The sequence stimuli used in SRTT can identify learning discrepancies, such as those between first and second-order conditional sequences. Furthermore, the use of virtual reality technologies to investigate along these lines could provide a more accurate picture of learning, which could easily extrapolate to natural settings. Linking statistical learning to language processing, particularly morphosyntactic aspects, can be considered a diagnostic and treatment process in PWA, which could better understand the processing of sequential information present in speech and language input.
ACKNOWLEDGMENTS
We thank the Director of All India Institute of Speech and Hearing (affiliated to University of Mysore) for permitting us to carry out the research.